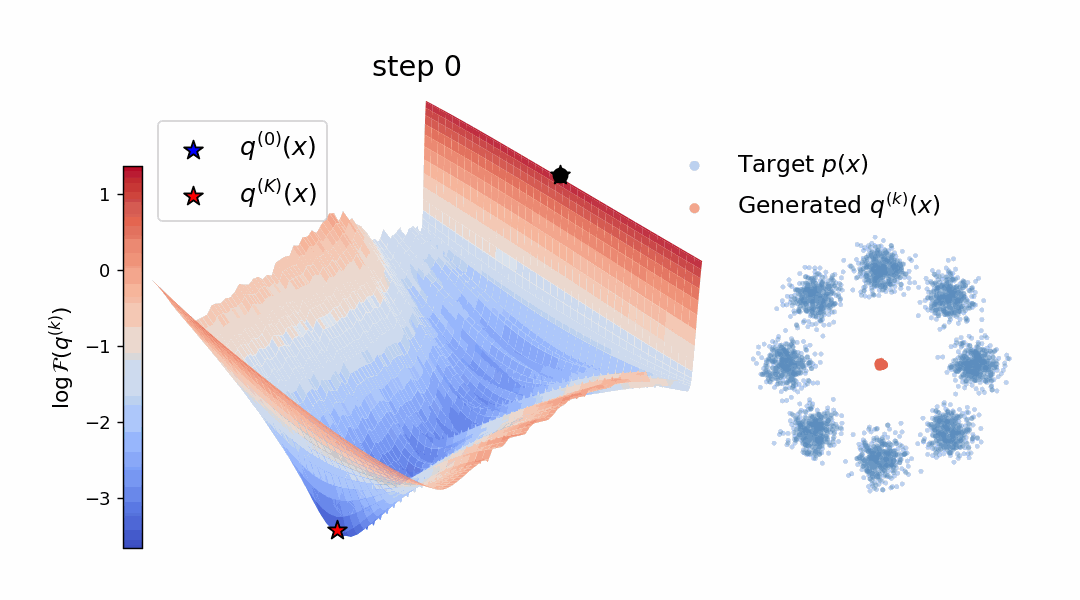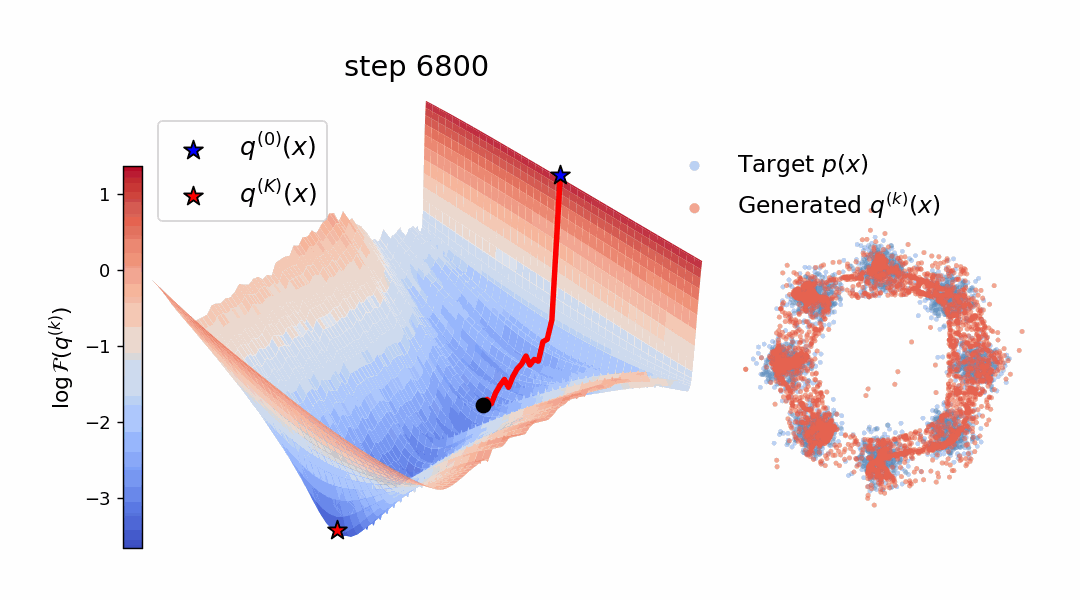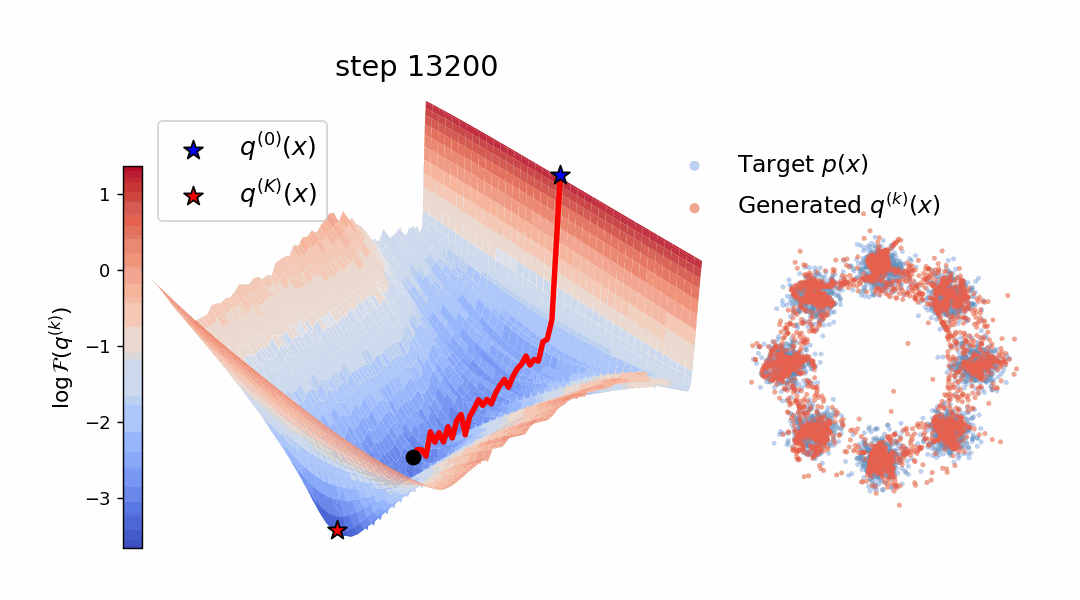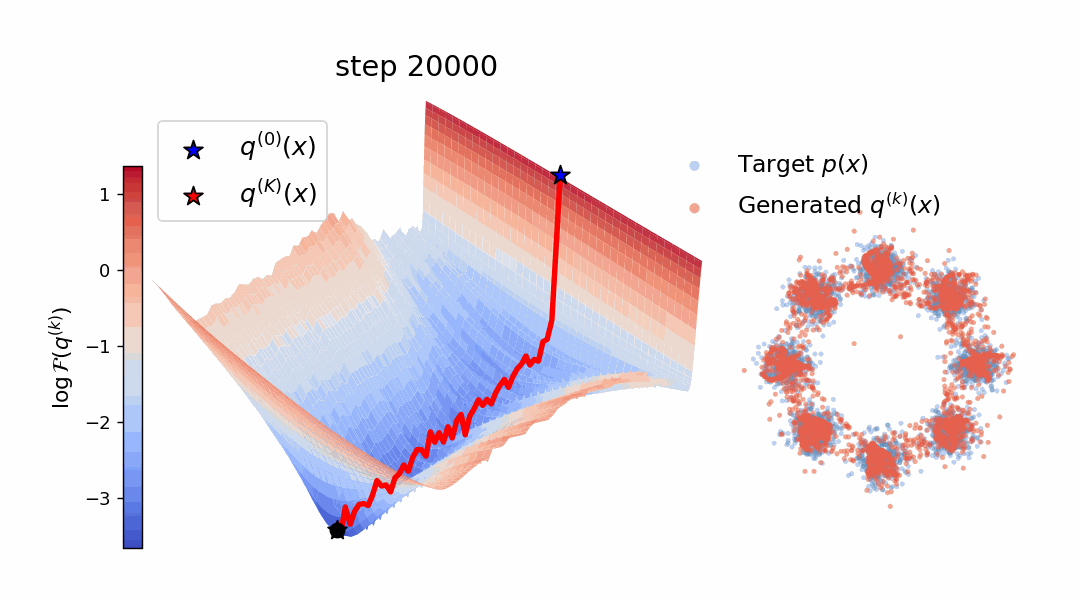
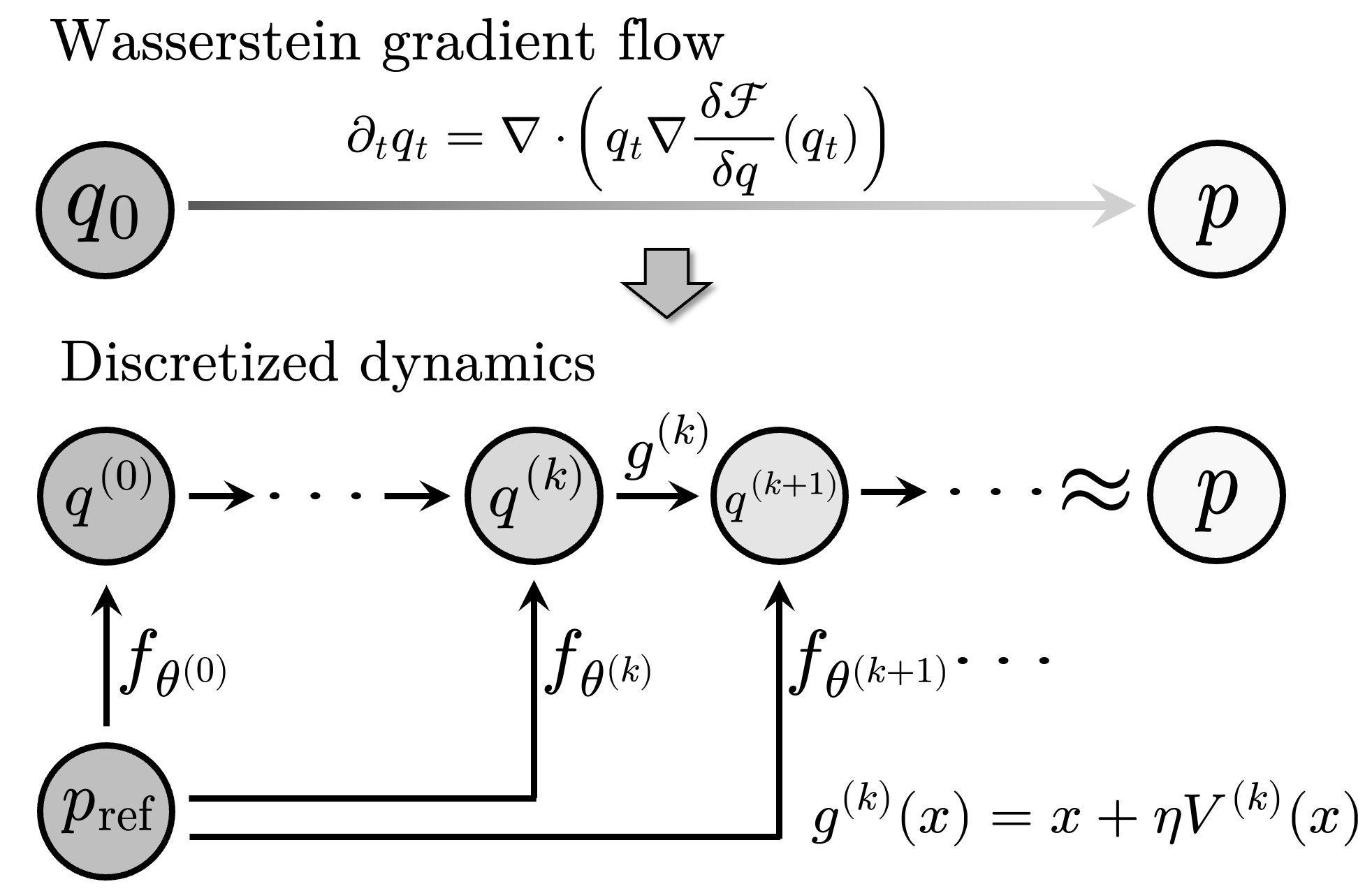
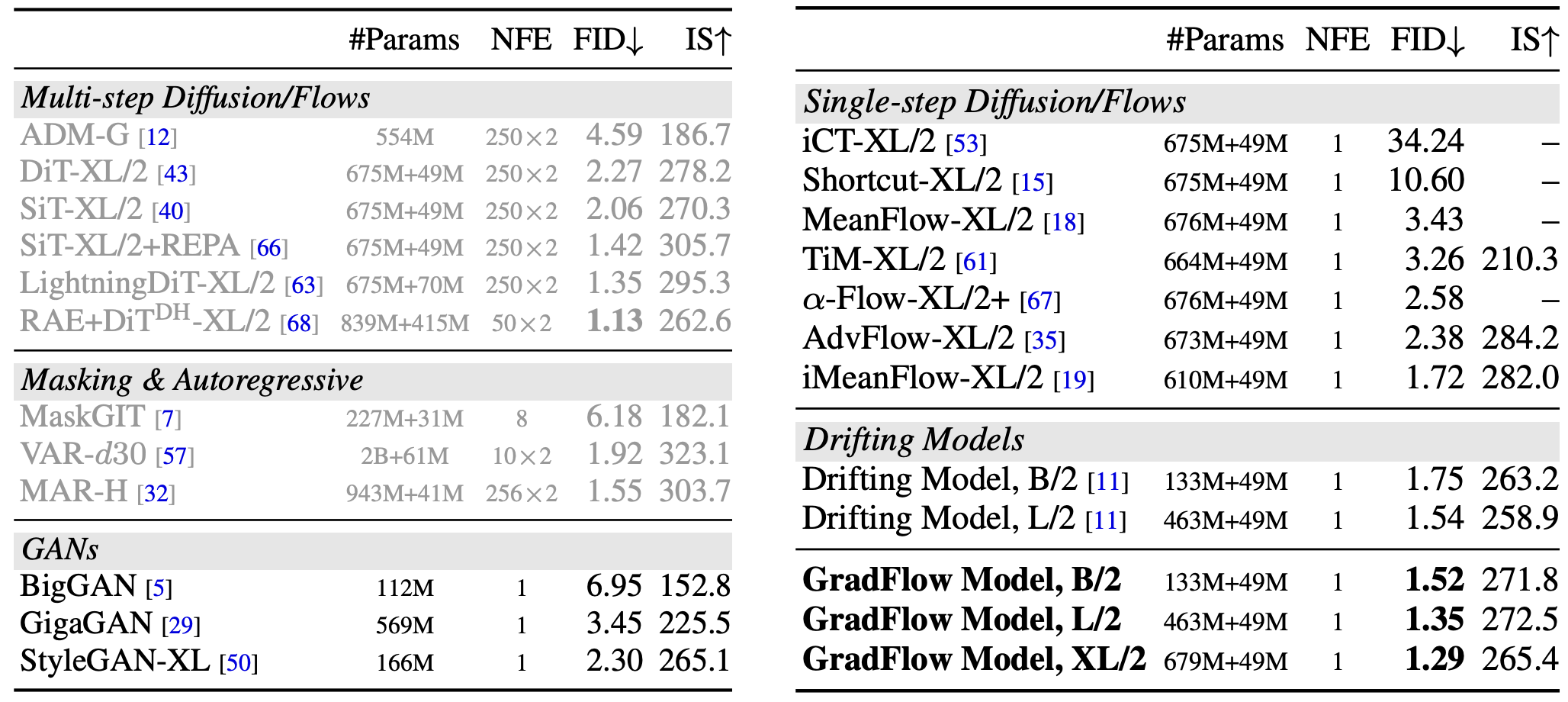
Diffusion models and flow-based methods have shown impressive generative capability,
especially for images, but their sampling is expensive because it requires many
iterative updates. We introduce W-Flow, a framework for training a generator that
transforms samples from a simple reference distribution into samples from a target
data distribution in a single step.
This is achieved in two steps: we first define
an evolution from the reference distribution to the target distribution through a
Wasserstein gradient flow that minimizes an energy functional; second, we train
a static neural generator to compress this evolution into one-step generation. We
instantiate the energy with the Sinkhorn divergence, which yields an efficient
optimal-transport-based update rule that captures global distributional discrepancy
and improves coverage of the target distribution. We further prove that the finite-
sample training dynamics converge to the continuous-time distributional dynamics
under suitable assumptions.
Empirically, W-Flow sets a new state of the art for
one-step ImageNet 256×256 generation, achieving 1.29 FID, with improved mode
coverage and domain transfer. Compared to multi-step diffusion models with
similar FID scores, our method yields approximately 100× faster sampling. These
results show that Wasserstein gradient flows provide a principled and effective
foundation for fast and high-fidelity generative modeling.